


开源人工智能技术开发商 DeepSeek 上周已经预告将在本周陆续推出 5 个已经在生产环境中使用的技术,目前首个项目 FlashMLA 已经在 GitHub 上公布。
FlashMLA 是一种针对 NVIDIA Grace Hopper 架构 GPU 设计的高效多层注意力 (Multi-Layer Attention,MLA) 解码内核,该技术不仅可以优化变长序列的处理性能,还可以将低内存占用和计算开销。
技术的关键特点包括:
BF16 支持:FlashMLA 采用 BF16 精度格式,兼顾 FP32 的动态范围和 FP16 的计算效率,这种设计可以显著降低内存占用和计算开销,特别适合深度学习模型的推理阶段。
分页 KV 缓存技术:Paged KV Cache 通过块大小为 64 的分页键缓存系统,FlashMLA 优化了 Transformer 模型中键值对的存储和访问,减少内存碎片和延迟等,这项技术主要是和处理变长序列,确保在不同输入长度下都能保持高效性能。
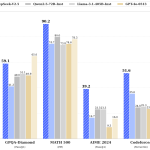
卓越性能:在 NVIDIA H800 GPU 上,FlashMLA 实现了 3000GB / 秒的内存带宽利用率 (内存限制场景) 和 580TFLOPS 的计算能力 (计算限制场景),数据表明 FlashMLA 可以充分利用 Hopper 架构的 HBM 高带宽内存和并行计算能力。
FlashMLA 优化变长序列带来的优势:
变长序列是自然语言处理、语音识别、时间序列分析等领域面临的常见技术挑战,传统模型在处理不固定长度的输入时往往效率会比较低,FlashMLA 通过针对性优化可以提高大型模型在变长序列场景下的推理速度,因此适合用于需要实时响应和高吞吐量的应用。
也就是说借助这项优势未来其他模型也可以优化响应速度,尤其是实时语音模式这种对响应速度有要求的场景,AI 可以更快的回答而不是让用户长时间等待。
目前 FlashMLA 已经在 GitHub 上完全开源,开发者只需要使用简单的 Python 命令即可快速部署,DeepSeek 也提供了测试脚本用来验证性能:https://github.com/deepseek-ai/FlashMLA
该项目的开源特性还借鉴了 FlashAttention 2&3 以及 CUTLASS 项目的模块化设计,有兴趣的开发者也可以研究上游项目的具体细节。



评论 (0)