


2026年5月下旬,一款名为 Qwen3.6-35B-A3B-Uncensored 的模型在开源社区迅速走红。
官方版有内容审核?这个版本,直接输出,不做限制。
保留了完整的推理和代码能力,同时移除了安全对齐限制。
---
⚡ 核心优势:MoE架构
35B总参数,每次推理只激活约3B。
实测 RTX 4060 Laptop(8G显存)跑 IQ2_M 量化版,输出速度约 10 tokens/s。
显存门槛:6G 可跑,12G+ 推荐 Q4_K_L。
---
📊 核心数据对比
35B 参数 / 3B 激活 / 6G 显存门槛 / 开源 / 无审查
Qwen3.6 官方版
35B 参数 / 3B 激活 / 6G 显存门槛 / 开源 / 有内容审核
GPT-5.5(闭源参考)
参数未公开 / API only / 收费 / 原生Agent能力
Llama 4 Ultra
约400B参数 / 约50B激活 / 24G+显存 / 开源 / 多模态强化
---
👁️ 视觉能力
支持多模态,挂载 mmproj 文件后即可分析图片、OCR、截图问答。
---
🚀 快速上手
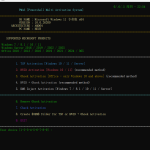
① 下载 llama.cpp(选对应CUDA版本)
② 下载 GGUF 模型文件
③ 双击 run.bat,浏览器打开 http://127.0.0.1:8080
④ 支持 OpenAI API 格式,可接入 OpenWebUI、Cherry Studio
显存推荐:
6-8G → IQ2_M
12-16G → Q4_NL(推荐)
24G+ → Q4_K_P
---
🔗 相关链接
模型下载:
https://huggingface.co/HauhauCS/Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive
Qwen3.6 官方:
https://github.com/QwenLM/Qwen3.6
llama.cpp:
https://github.com/ggerganov/llama.cpp
---
适合本地研究、安全测试、以及真正需要模型"说实话"的场景。
能力没有打折——代码生成、多模态识图、长文本推理均保持高水准。



评论 (0)